
※ 이 글에는 제휴 마케팅 링크가 포함될 수 있으며, 구매 시 수수료를 받을 수 있습니다.
매달 클라우드 청구서를 열 때마다 “AI 항목"이 조용히 불어나 있는 걸 발견한 적이 있나요? 문제는 AI 지출이 기존 IT 예산을 대체하는 게 아니라 완전히 새로운 비용 계층을 위에 쌓는다는 점입니다. 이 글에서는 AI 비용이 어디서 새는지, 그리고 모델 라우팅·캐싱·배치·RAG 같은 검증된 기법으로 그 비용을 어떻게 절반 이하로 줄이는지를 출처와 함께 정리했습니다.
왜 지금 ‘AI 지출 관리’가 화두인가
AI 비용을 관리 대상으로 본격 편입한 조직이 폭발적으로 늘고 있습니다. FinOps(클라우드 재무 운영) 팀 중 AI 지출을 관리하는 비율이 1년 만에 31%에서 63%로 두 배 이상 증가했습니다 (출처: State of FinOps 2025). 더 중요한 신호는 비용의 성격입니다. 응답자의 97%가 AI를 위해 여러 인프라 영역에 동시 투자 중이며, AI 지출은 기존 예산을 대체하지 않고 새로운 비용 계층을 추가합니다 (출처:(https://portkey.ai/blog/the-state-of-ai-finops-2025-key-insights-from-finops-foundations-latest-report/)).
즉, “기존 서버 비용을 줄여 AI로 옮긴다"가 아니라 “원래 쓰던 것 + AI를 추가로 쓴다"가 현실입니다. 그래서 통제 장치 없이 도입하면 예산이 새는 게 아니라 구조적으로 초과됩니다. 다행히 이 새는 비용을 막는 기법은 이미 충분히 정립돼 있습니다.
핵심 비용 절감 기능과 도구별 한계
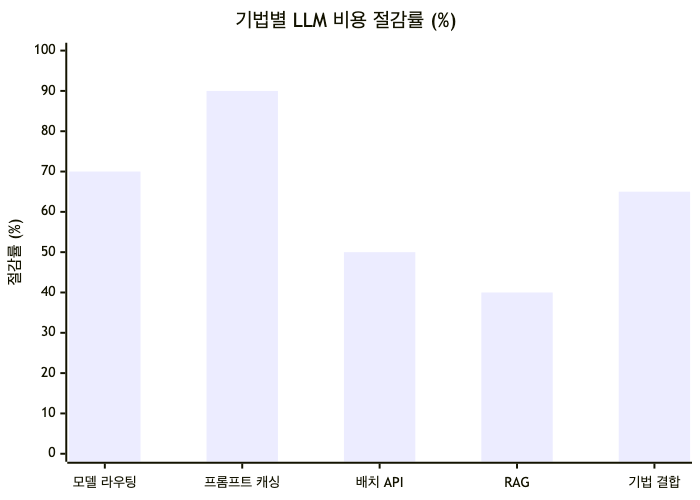
아래 다섯 가지는 LLM API 비용을 줄이는 핵심 레버입니다. 각 기법의 효과와 함께, 실무에서 마주치는 단점도 같이 짚습니다.
1. 모델 라우팅 (복잡도 기반 티어 분배)
모든 요청을 가장 비싼 모델로 처리할 필요는 없습니다. 쿼리 복잡도에 따라 모델을 라우팅(예: 70% 저가 모델, 20% 중급, 10% 프리미엄)하면 단일 프리미엄 모델 대비 쿼리당 평균 비용을 60~80% 절감할 수 있습니다 (출처: Morph, LLM Cost Optimization).
단점 ① 라우팅 판단 자체가 추가 로직(또는 분류용 소형 모델 호출)을 요구해, 잘못 설계하면 라우터가 새로운 지연·비용 요인이 됩니다. 단점 ② 저가 모델로 잘못 라우팅된 복잡한 쿼리는 품질 저하나 재시도를 유발해, 절감액을 깎아먹을 수 있습니다.
2. 프롬프트 캐싱 · 시맨틱 캐싱
같은 컨텍스트(시스템 프롬프트, 문서, 예시)를 반복 전송한다면 캐싱이 가장 직접적인 절감 수단입니다. Anthropic 프롬프트 캐싱은 TTL 내 재요청 시 표준 입력가의 **0.10배(90% 할인)**만 청구됩니다 (출처: Anthropic Prompt Caching).
단점 ① 캐싱은 반복되는 동일 컨텍스트에만 유효합니다. 매번 컨텍스트가 달라지는 워크로드에는 효과가 거의 없습니다. 단점 ② 캐시 ‘쓰기’에는 오히려 프리미엄이 붙습니다 — 캐시 쓰기는 표준 입력가의 1.25배(5분 TTL) 또는 2.0배(1시간 TTL)이므로 (출처: Anthropic Prompt Caching), 재사용 빈도가 낮으면 손해입니다.
3. 배치 API 비동기 처리
실시간 응답이 필요 없는 작업(대량 분류, 요약, 임베딩 생성 등)은 배치로 돌리면 큰 폭으로 저렴합니다. Anthropic Batch API는 입력·출력 토큰 모두 50% 할인(24시간 내 비동기 처리)이며 (출처: Anthropic Pricing), OpenAI Batch API 역시 전 모델 50% 할인입니다 (출처: Morph, LLM Cost Optimization).
단점 ① 배치는 실시간 응답이 필요 없는 비동기 작업에만 쓸 수 있어, 사용자 대면 챗봇 같은 즉시성 요구 워크로드에는 부적합합니다. 단점 ② 처리 완료까지 최대 24시간이 걸릴 수 있어, 결과를 기다리는 후속 파이프라인 설계가 복잡해집니다.
4. 프롬프트 압축 · RAG로 컨텍스트 축소
보내는 토큰 자체를 줄이는 접근입니다. 프롬프트 압축, 시맨틱 캐싱, 배치 처리, 지능형 모델 라우팅을 결합하면 LLM API 지출을 50~80% 줄일 수 있습니다 (출처: nOps, LLM Cost Optimization Tips). RAG 아키텍처는 작은 모델과 관련 컨텍스트만 사용해 요청당 비용을 30~50% 절감할 수 있습니다 (출처:(https://exadel.com/news/llm-cost-optimization-enterprise-ai-framework/)).
단점 ① 프롬프트 압축은 과도하게 줄이면 핵심 맥락이 손실돼 답변 품질이 떨어지는 트레이드오프가 있습니다. 단점 ② RAG는 벡터 DB·임베딩·검색 인프라라는 새 구성 요소를 추가하므로, 검색 품질이 나쁘면 “싼 모델 + 잘못된 컨텍스트 = 잘못된 답"이라는 새로운 실패 모드를 만듭니다.
5. 실시간 모니터링 · 예산 알림 · 이상 탐지 (FinOps)
절감 기법을 깔아도 가시성이 없으면 어디서 새는지 알 수 없습니다. FinOps 도구는 실시간 사용량 모니터링, 예산 임계치 알림, 비정상 급증 탐지를 제공합니다.
단점 ① AI 워크로드는 전통적 클라우드 서비스 대비 가격이 덜 투명하고 변동성이 커, 모니터링을 붙여도 비용 귀속(어느 팀·기능이 얼마 썼는지)이 어렵습니다 (출처:(https://portkey.ai/blog/the-state-of-ai-finops-2025-key-insights-from-finops-foundations-latest-report/)). 단점 ② 거버넌스·정책이 따라오지 않으면 알림만 쌓이고 실제 행동으로 이어지지 않습니다.
단점 · 한계 (도입 전 반드시 알아둘 것)
절감 기법은 만능이 아닙니다. 도구별로 명확한 한계가 있습니다.
가격 불투명성과 변동성 — AI 워크로드는 전통적 클라우드 서비스 대비 가격이 덜 투명하고 변동성이 커, 많은 실무자가 AI 사용량·비용에 대한 명확한 가시성 확보에 어려움을 겪습니다 (출처:(https://portkey.ai/blog/the-state-of-ai-finops-2025-key-insights-from-finops-foundations-latest-report/)). 즉, 절감 전에 ‘측정’부터가 난관입니다.
캐싱·배치 할인의 적용 범위 제약 — 프롬프트 캐싱·배치 할인은 모든 워크로드에 적용되지 않습니다. 캐싱은 반복되는 동일 컨텍스트에만 유효하고, 배치는 실시간 응답이 필요 없는 비동기 작업에만 쓸 수 있습니다 (출처: Anthropic Prompt Caching). 실시간 대면 서비스 비중이 높은 조직은 절감 폭이 제한적입니다.
거버넌스 부재 — 대부분 기업이 AI 비용을 효과적으로 추적할 가시성·통제 수단을 아직 갖추지 못해, 거버넌스·정책 수립이 향후 최우선 과제로 떠오르고 있습니다 (출처: State of FinOps 2025). 기술만 도입하고 정책이 없으면 절감은 일회성에 그칩니다.
라우팅·RAG의 품질 리스크 — 비용을 낮추려고 저가 모델·압축·검색 의존도를 높이면, 잘못된 라우팅이나 검색 실패가 품질 저하와 재시도를 부르는 새로운 실패 모드를 만듭니다.
요금 · 한도 (출처 링크 포함)
각 절감 수단의 실제 가격 구조입니다. 모든 수치에 출처 링크를 달았습니다.
- Anthropic Batch API: 입력·출력 토큰 모두 50% 할인 (24시간 내 비동기 처리) (platform.claude.com/docs)
- Anthropic 프롬프트 캐시 쓰기: 표준 입력가의 1.25배(5분 TTL) / 2.0배(1시간 TTL) (platform.claude.com/docs)
- Anthropic 프롬프트 캐시 읽기: 표준 입력가의 0.10배(90% 할인) (platform.claude.com/docs)
- OpenAI Batch API: 전 모델 50% 할인 (morphllm.com)
- 모델 라우팅 절감 효과: 단일 프리미엄 모델 대비 쿼리당 평균 60~80% (morphllm.com)
- 기법 결합 절감 효과: LLM API 지출 50~80% (nops.io)
- RAG 절감 효과: 요청당 30~50% (exadel.com)
참고: 위 할인율은 정책에 따라 변동될 수 있으므로, 실제 적용 전 각 공급사 공식 가격 페이지에서 최신 수치를 확인하세요.
비교표: 절감 기법 한눈에 보기
| 기법 | 절감 효과 | 적용 워크로드 | 주요 한계 | 출처 |
|---|---|---|---|---|
| 모델 라우팅 | 쿼리당 60~80% | 복잡도가 다양한 혼합 요청 | 라우터 오분류 시 품질 저하 | morphllm.com |
| 프롬프트 캐싱 | 캐시 읽기 90% (0.10배) | 동일 컨텍스트 반복 | 캐시 쓰기 1.25~2.0배 프리미엄 | Anthropic |
| 배치 API | 입출력 50% | 비실시간 대량 처리 | 최대 24시간 지연 | Anthropic |
| RAG | 요청당 30~50% | 지식 기반 질의응답 | 벡터 인프라·검색 품질 의존 | exadel.com |
| 기법 결합 | 50~80% | 다수 워크로드 통합 | 운영 복잡도 증가 | nops.io |
추천 대상
- AI 청구서가 매달 예측 불가능하게 늘어나는 조직 — 먼저 FinOps 모니터링으로 가시성을 확보한 뒤 라우팅·캐싱을 붙이는 순서를 권합니다.
- 동일 시스템 프롬프트/문서를 반복 사용하는 서비스 (사내 챗봇, 문서 Q&A) — 프롬프트 캐싱의 0.10배 읽기 할인 효과가 가장 큽니다.
- 야간·대량 처리 파이프라인을 운영하는 팀 (리포트 생성, 대량 분류·요약) — 배치 API 50% 할인으로 즉시 비용을 반으로 줄일 수 있습니다.
- 사내 지식 기반 위에 AI를 얹는 조직 — RAG로 작은 모델 + 관련 컨텍스트 조합을 설계하면 요청당 비용을 크게 낮출 수 있습니다.
반대로, 거의 모든 요청이 실시간·고품질을 요구하고 컨텍스트가 매번 달라지는 서비스라면 캐싱·배치 효과가 제한적이므로, 모델 라우팅과 모니터링 위주로 접근하는 편이 현실적입니다.
자주 묻는 질문 (FAQ)
Q1. 어떤 기법부터 적용해야 절감 효과가 가장 빠른가요? A. 측정이 먼저입니다. AI 비용은 가격 투명성이 낮아 가시성 확보 자체가 난관이므로 (출처:(https://portkey.ai/blog/the-state-of-ai-finops-2025-key-insights-from-finops-foundations-latest-report/)), FinOps 모니터링으로 어디서 새는지 파악한 뒤, 비실시간 대량 작업이 있으면 배치 API(50% 할인)부터, 반복 컨텍스트가 있으면 캐싱부터 적용하는 것이 빠릅니다.
Q2. 모델 라우팅으로 정말 60~80%를 줄일 수 있나요? A. 쿼리 복잡도 분포가 라우팅에 적합할 때(예: 70% 저가 / 20% 중급 / 10% 프리미엄) 단일 프리미엄 모델 대비 쿼리당 평균 60~80% 절감이 보고됩니다 (출처: Morph). 다만 모든 요청이 고난도라면 절감 폭은 줄어듭니다.
Q3. 프롬프트 캐싱은 무조건 이득인가요? A. 아닙니다. 캐시 읽기는 0.10배로 매우 저렴하지만 캐시 쓰기는 1.25~2.0배 프리미엄이 붙으므로 (출처: Anthropic), 동일 컨텍스트가 TTL 내에 충분히 자주 재사용될 때만 이득입니다. 매번 컨텍스트가 바뀌면 오히려 손해일 수 있습니다.