
※ 이 글에는 제휴 마케팅 링크가 포함될 수 있으며, 구매 시 수수료를 받을 수 있습니다.
AI를 본격적으로 쓰기 시작하면 가장 먼저 부딪히는 벽이 ‘비용’입니다. 개인은 매달 빠져나가는 구독료가, 서비스를 운영하는 개발자는 사용량에 비례해 불어나는 API 청구서가 부담이 되죠. 그런데 같은 결과물을 만들면서도 비용을 60~80%까지 줄일 수 있는 방법들이 이미 존재합니다. 이 글에서는 프롬프트 캐싱, Batch API, 모델 라우팅 같은 핵심 절감 기법부터 개인 구독 티어를 똑똑하게 고르는 법까지, 불필요한 AI 지출을 걷어내는 실전 전략을 정리했습니다.
AI 비용은 왜 이렇게 빨리 불어날까
AI 비용은 크게 두 갈래입니다. 하나는 ChatGPT Plus, Claude Pro 같은 월 정액 구독료이고, 다른 하나는 서비스에 AI를 붙여 쓸 때 발생하는 토큰 단위 API 비용입니다. 개인 사용자라면 보통 구독료만 신경 쓰면 되지만, 자동화 워크플로우나 앱에 AI를 연결하는 순간부터는 토큰 비용이 진짜 변수가 됩니다.
토큰 비용이 무서운 이유는 ‘반복’ 때문입니다. 매 요청마다 동일한 시스템 프롬프트나 긴 참고 문서를 통째로 다시 보내면, 똑같은 입력을 매번 새 가격으로 결제하는 셈이 됩니다. 절감의 핵심은 바로 이 반복과 낭비를 걷어내는 데 있습니다.
핵심 절감 기능 — 무엇을 어떻게 줄이나
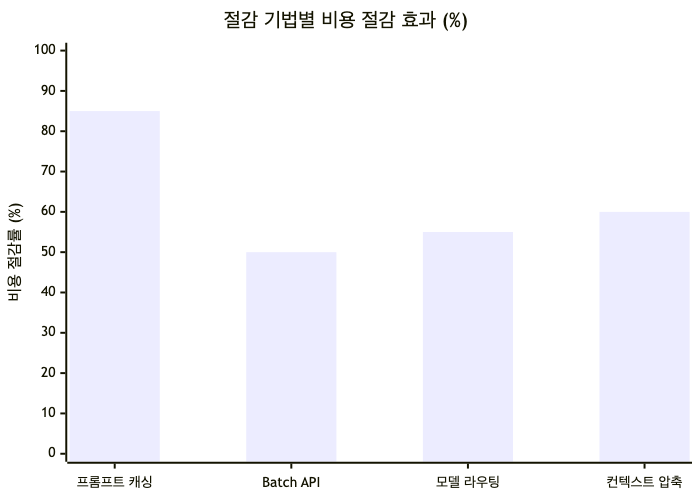
1. 프롬프트 캐싱 (Prompt Caching)
가장 효과가 큰 기법입니다. 시스템 프롬프트나 문서 프리픽스처럼 매번 똑같이 반복되는 입력을 캐시에 저장해두고 재사용하면, 캐시 읽기 비용이 기본 가격의 약 10% 수준으로 떨어집니다. Anthropic의 프롬프트 캐싱은 이 방식으로 대용량 고정 컨텍스트 앱의 입력 토큰 비용을 80~90%까지 절감할 수 있습니다(morphllm.com).
OpenAI에서도 마찬가지로 작동합니다. 프롬프트 캐싱과 배치 할인은 서로 독립적으로 중첩 적용되며, 둘 다 켜면 GPT-5.4 캐시 입력 토큰이 100만 토큰당 $0.625로, 표준 $2.50 대비 75% 감소합니다(tokenmix.ai).
단점 2가지:
- 절감 효과는 시스템 프롬프트나 문서 프리픽스처럼 반복되는 대용량 고정 컨텍스트가 있을 때만 크게 나타납니다. 매번 질의 내용이 통째로 바뀌는 패턴에서는 효과가 제한적입니다(morphllm.com).
- 캐시는 보통 일정 시간이 지나면 만료되므로, 호출 빈도가 낮으면 캐시가 살아 있기 전에 사라져 이점을 못 누릴 수 있습니다.
2. Batch API — 급하지 않은 작업은 절반 가격으로
Anthropic과 OpenAI의 Batch API는 요청을 비동기로 처리하는 대신 50% 할인을 제공합니다. 결과는 실시간이 아니라 24시간 이내에 도착합니다(OpenAI Batch 가이드). 대량 데이터 분류, 문서 요약, 정기 리포트 생성처럼 ‘지금 당장’이 아니어도 되는 작업이라면 그냥 절반을 깎고 들어가는 셈입니다.
단점 2가지:
- 결과가 최대 24시간 뒤에 도착하므로, 사용자가 화면 앞에서 즉시 응답을 기다리는 채팅·실시간 워크로드에는 부적합합니다(OpenAI Batch 가이드).
- 작업을 ‘실시간’과 ‘배치’로 분류하고 큐를 관리하는 추가 설계가 필요해, 단순한 즉답형 서비스에는 오히려 번거로울 수 있습니다.
3. 모델 라우팅 — 쉬운 질문에 비싼 모델 쓰지 않기
모든 질문에 최상위 플래그십 모델을 쓸 필요는 없습니다. 간단한 분류나 짧은 답변은 저가·소형 모델로 보내고, 복잡한 추론만 고가 모델로 올리는 ‘모델 라우팅’을 적용하면 토큰 비용을 40~70% 줄일 수 있습니다(morphllm.com).
단점 2가지:
- 질의 난이도를 잘못 판별해 어려운 작업을 소형 모델로 보내면 품질이 떨어지고, 결국 재요청으로 비용이 더 나갈 수 있습니다.
- 라우팅 로직 자체를 만들고 유지보수해야 하므로, 소규모 프로젝트에서는 관리 부담이 절감액을 상쇄할 수 있습니다.
4. 컨텍스트 압축 & 출력 토큰 최적화
대화 기록이나 참고 문서를 통째로 보내는 대신 핵심만 요약해 보내는 컨텍스트 압축은 토큰 비용을 50~70% 줄일 수 있습니다(morphllm.com). 여기에 “간결하게 답하라"처럼 출력 길이를 제어해 불필요하게 긴 응답을 막으면 출력 토큰까지 함께 아낄 수 있습니다.
이 네 가지를 함께 적용하면 대부분의 프로덕션 앱이 LLM API 비용을 60~80% 절감할 수 있습니다(morphllm.com).
단점 / 한계 — 절감 기법의 그림자
절감 기법은 만능이 아닙니다. 적용 전에 반드시 알아둬야 할 트레이드오프가 있습니다.
Batch API의 지연: 50% 할인의 대가는 ‘시간’입니다. 결과가 최대 24시간 뒤에 오므로, 즉시 응답이 필요한 워크로드에는 쓸 수 없습니다. 실시간성과 비용 중 하나를 골라야 하는 구조입니다(OpenAI Batch 가이드).
프롬프트 캐싱의 조건 의존성: 캐싱은 반복되는 고정 컨텍스트가 있을 때만 빛을 봅니다. 매번 질의 패턴이 달라지는 서비스에서는 절감 폭이 작거나 거의 없습니다(morphllm.com).
무료 티어의 엄격한 제한: ‘그냥 무료로 쓰면 되지’라는 접근은 한계가 분명합니다. ChatGPT 무료는 5시간마다 제한된 메시지를 쓰면 소형 모델로 전환되고, Gemini와 Claude의 무료 플랜도 수요에 따라 변하는 세션·주간 한도가 있습니다(sentisight.ai). 업무에 꾸준히 쓰려면 결국 유료 티어가 필요해지는 경우가 많습니다.
모델 라우팅의 품질 리스크: 저가 모델로의 분기는 비용을 줄이지만, 난이도 판별이 틀리면 답변 품질이 떨어집니다. 절감액과 품질 사이의 균형점을 직접 튜닝해야 합니다.
요금 / 한도 — 개인 구독 티어 정리
2026년 AI 구독 시장은 각 제공사의 플래그십 모델에 접근하는 월 $20 표준 티어를 중심으로 형성되었습니다(sentisight.ai). 개인 사용자라면 이 표준 티어 하나로 대부분의 작업이 커버됩니다.
- Claude Pro (개인): 월 $20(월별 결제), 연간 결제 시 월 $17($200 선결제)(claude.com/pricing)
- Claude Max: 월 $100부터 (Pro 대비 5배 또는 20배 사용량)(claude.com/pricing)
- ChatGPT Plus: 월 $20(sentisight.ai)
- ChatGPT Pro: 월 $200 (고급 추론 모델 무제한)(sentisight.ai)
- Google AI Pro: 월 $19.99 (구 Gemini Advanced)(sentisight.ai)
- Google AI Ultra: 월 $249.99(sentisight.ai)
비용 최적화 포인트: Claude Pro처럼 연간 결제로 월 $20 → $17로 낮추는 옵션이 있다면, 1년 이상 꾸준히 쓸 계획일 때 약 15% 절약됩니다(claude.com/pricing). 반대로 사용 빈도가 들쭉날쭉하다면 월별 결제로 유연성을 확보하는 편이 낫습니다.
비교표 — 절감 기법 한눈에 보기
| 절감 기법 | 절감 폭 | 적합한 상황 | 핵심 트레이드오프 |
|---|---|---|---|
| 프롬프트 캐싱 | 입력 토큰 80~90% | 반복되는 고정 시스템 프롬프트·문서 | 변동 질의엔 효과 제한 |
| Batch API | 50% | 급하지 않은 대량 처리 | 결과 최대 24시간 지연 |
| 모델 라우팅 | 40~70% | 난이도 편차가 큰 질의 혼합 | 판별 오류 시 품질 저하 |
| 컨텍스트 압축 | 50~70% | 긴 대화·문서 컨텍스트 | 요약 과정에서 정보 손실 가능 |
| 통합 적용 | 60~80% | 프로덕션 앱 전반 | 설계·관리 복잡도 증가 |
출처: 절감 폭 수치는 morphllm.com 및 OpenAI Batch 가이드 기준.
추천 대상 — 누구에게 어떤 전략이 맞나
가끔 쓰는 개인 사용자: 무료 티어로 시작하되, 한도 전환(소형 모델로 다운그레이드)이 불편해지는 순간 월 $20 표준 티어 하나만 구독하세요. 여러 서비스를 동시에 결제하는 건 대개 낭비입니다.
매일 업무에 쓰는 헤비 유저: 한 제공사의 월 $20 티어를 메인으로 삼고, 사용량 한도에 자주 막힌다면 Claude Max(월 $100부터)처럼 상위 티어로 올리는 것이 여러 구독을 중복하는 것보다 효율적일 수 있습니다(claude.com/pricing).
AI를 서비스에 연결하는 개발자·운영자: 프롬프트 캐싱 → 모델 라우팅 → Batch API 순서로 적용하세요. 고정 컨텍스트가 큰 앱이라면 캐싱만으로도 입력 비용 대부분이 빠지고, 비실시간 배치 작업을 분리하면 여기서 또 절반이 깎입니다.
비용에 민감한 자동화 운영자: 급하지 않은 모든 작업을 Batch API로 몰고, 출력 길이를 명시적으로 제한해 토큰 낭비를 막는 것이 가장 빠른 절감 경로입니다.
자주 묻는 질문 (FAQ)
Q1. 프롬프트 캐싱과 Batch API를 동시에 쓸 수 있나요? 네. OpenAI에서 프롬프트 캐싱과 배치 할인은 서로 독립적으로 중첩 적용됩니다. 둘 다 켜면 GPT-5.4 캐시 입력 토큰이 표준 대비 75% 감소합니다(tokenmix.ai). 단, 실시간 응답이 필요한 작업은 배치에 넣을 수 없으니 작업 성격에 따라 나눠야 합니다.
Q2. 무료 티어만으로 버틸 수 있을까요? 가벼운 사용이라면 가능하지만, 무료 플랜은 한도가 엄격합니다. ChatGPT 무료는 일정 메시지 이후 소형 모델로 전환되고, Gemini·Claude 무료도 수요에 따라 변하는 세션·주간 한도가 있습니다(sentisight.ai). 꾸준한 업무용이라면 월 $20 표준 티어 하나가 현실적입니다.
Q3. 개인인데 API 절감 기법(캐싱·배치)이 저에게도 의미 있나요? 직접 API를 호출하지 않고 ChatGPT·Claude 앱만 쓴다면 캐싱·배치는 제공사가 내부적으로 처리하므로 신경 쓸 필요가 없습니다. 이 기법들은 자동화 워크플로우나 앱에 AI를 연결해 토큰 단위로 결제하는 경우에 직접적인 절감 효과가 큽니다. 개인 사용자에게는 ‘구독 티어를 용도에 맞게 고르는 것’이 가장 확실한 절약입니다.
참고 링크
- LLM 비용 최적화 가이드 (프롬프트 캐싱·모델 라우팅·압축): https://www.morphllm.com/llm-cost-optimization
- OpenAI Batch API 공식 가이드: https://developers.openai.com/api/docs/guides/batch
- OpenAI Batch API 가격 분석: https://tokenmix.ai/blog/openai-batch-api-pricing
- Claude 요금제: https://claude.com/pricing
- AI 구독 가격 비교 (Gemini·ChatGPT·Claude·Grok): https://www.sentisight.ai/ai-price-comparison-gemini-chatgpt-claude-grok/
본문의 가격·절감 수치는 명시된 출처 기준이며, 요금제와 모델 정책은 각 제공사 사정에 따라 변동될 수 있으므로 결제 전 공식 페이지에서 최신 정보를 확인하시기 바랍니다. 이 글은 정보 제공용이며 특정 수익이나 결과를 보장하지 않습니다.