
※ 이 글에는 제휴 마케팅 링크가 포함될 수 있으며, 구매 시 수수료를 받을 수 있습니다.
AI 에이전트를 만들어 본 사람이라면 한 번쯤 겪는 공포가 있습니다. 로컬 테스트에서는 완벽하게 동작하던 에이전트가, 실제 사용자 환경에 배포되는 순간 엉뚱한 버튼을 누르고 잘못된 결제를 시도하며 무한 루프에 빠집니다. Patronus AI는 바로 이 지점을 겨냥합니다. 자율주행차를 도로에 내보내기 전 시뮬레이터에서 수백만 번 주행시키듯, AI 에이전트를 ‘디지털 월드’라는 복제된 환경에서 먼저 박살 내 보자는 발상입니다. 이 글에서는 AI 에이전트 개발자 관점에서 Patronus AI의 핵심 기능, 한계, 요금 구조를 정리합니다.
Patronus AI는 무엇을 하는가
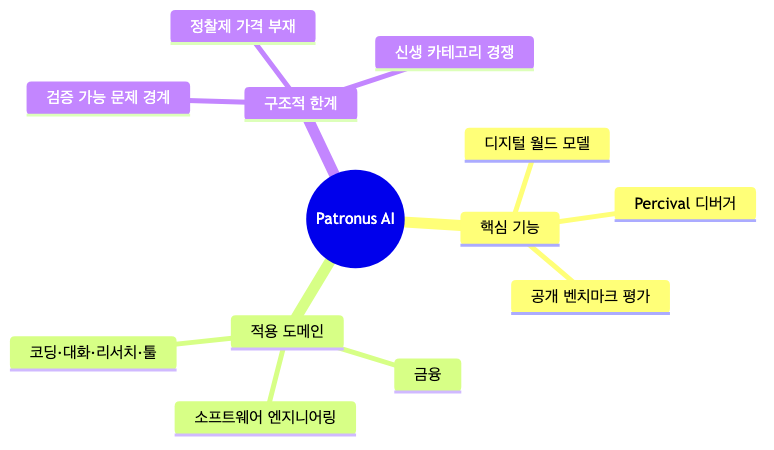
Patronus AI의 핵심은 **디지털 월드 모델(digital world models)**입니다. 웹사이트나 기업 내부 시스템을 시뮬레이션으로 복제한 뒤, 실제 배포 전에 그 안에서 AI 에이전트를 스트레스 테스트합니다. (출처: techcrunch.com) 회사는 이 접근을 자율주행 기업 Waymo가 합성 환경에서 차량을 훈련시키는 방식에 직접 비유합니다. 즉, 실제 트래픽이나 실제 고객 계정에 에이전트를 노출하기 전에, 위험 없는 가상 공간에서 먼저 실패시켜 본다는 것입니다.
이 시뮬레이션 환경 안에서 에이전트는 **강화학습(RL)**으로 훈련됩니다. 작업을 성공하면 보상을 주고, 오류를 내면 페널티를 주는 방식으로 반복 학습하며, 특히 코딩·대화·리서치·툴 사용처럼 여러 단계가 길게 이어지는 ‘ultra-long horizon’ 워크플로에 초점을 맞춥니다. (출처: techcrunch.com) 더 흥미로운 점은 이 평가가 사람 개입 없이(without any human involvement) 자동으로 이뤄진다는 것입니다. 사람이 일일이 trace를 들여다보며 채점하는 대신, 시스템이 에이전트의 행동을 자동으로 판정합니다.
핵심 기능 1 — 디지털 월드 모델과 language diffusion world models
디지털 월드 모델은 단순한 목업이 아니라 웹사이트·기업 내부 시스템의 동작을 흉내 내는 시뮬레이션 복제본입니다. 여기에 language diffusion world models를 결합해 현실적인 환경 행동을 예측하고, 에이전트의 행동을 거기에 맞춰 조정합니다. (출처: patronus.ai) 개발자는 dwm.patronus.ai/playground에서 Playground 접근을 통해 이 환경을 직접 다뤄볼 수 있습니다.
다만 이 기능에는 분명한 단점이 있습니다. 첫째, RL 환경 복제의 기술적 세부사항이 공개되어 있지 않습니다. 시리즈 B 발표문과 공식 사이트 어디에도 어떤 방식으로 내부 시스템을 충실하게 복제하는지, 그 충실도(fidelity)를 어떻게 검증하는지에 대한 구체적 설명이 없습니다. (출처: patronus.ai) 시뮬레이션 환경이 실제 프로덕션과 미묘하게 다르면, 거기서 통과한 에이전트가 실제 환경에서 다시 실패할 수 있습니다. 둘째, 적용 도메인이 좁습니다. 현재 강점이 소프트웨어 엔지니어링·금융 등 일부 영역에 집중되어 있어, 그 밖의 도메인에서는 복제 품질이 검증되지 않았습니다. (출처: techcrunch.com)
핵심 기능 2 — Percival 디버거
Percival은 에이전트의 실행 추적(trace)을 분석하는 디버깅 도구입니다. 에이전트가 남긴 trace에서 20개 이상의 실패 모드를 감지하고 최적화를 제안하며, 사람이 직접 워크플로를 분석하던 시간을 약 1시간에서 1~90초로 단축했다고 회사는 밝힙니다. (출처: patronus.ai/percival) 에이전트가 왜 잘못된 경로로 빠졌는지를 수동으로 로그를 뒤지며 찾던 개발자에게는 매력적인 자동화입니다.
이 도구에도 한계가 있습니다. 첫째, ‘20개 이상의 실패 모드’가 무엇인지, 어떤 분류 체계인지가 외부에 상세히 공개되지 않아 자신의 에이전트가 가진 특수한 실패 유형이 그 안에 포함되는지 사전에 확인하기 어렵습니다. (출처: patronus.ai/percival) 둘째, ‘1~90초’라는 범위 자체가 매우 넓어, 복잡한 워크플로에서는 실제로 어느 정도 시간이 걸리는지 예측하기 어렵고 단축 효과가 사례별로 크게 갈릴 수 있습니다. (회사가 제시한 범위의 폭을 근거로 한 추정)
핵심 기능 3 — 공개 벤치마크 기반 평가
Patronus는 자체 환경뿐 아니라 InterCode, τ-bench, SWE-smith, DeepResearchQA 같은 공개 벤치마크를 활용해 코딩·대화·리서치·툴 사용 도메인을 다룹니다. (출처: patronus.ai) 표준 벤치마크를 끼고 있다는 것은 평가 결과를 외부와 비교할 수 있는 기준점이 생긴다는 점에서 긍정적입니다.
여기서도 두 가지 약점이 보입니다. 첫째, 공개 벤치마크는 정의상 ‘검증 가능한’ 문제에 치우쳐 있습니다. 뒤에서 다루겠지만 창업자 본인이 검증이 어렵거나 불가능한 영역이 훨씬 많다고 인정한 만큼, 벤치마크 점수가 높다고 실제 운영 안전성을 보장하지는 않습니다. (출처: techcrunch.com) 둘째, 구체적인 고객 명단이 공개되지 않아 이 벤치마크 평가가 실제 프로덕션 환경에서 어떤 성과로 이어졌는지 제3자가 검증하기 어렵습니다. (출처: patronus.ai)
단점과 한계 — 도입 전 반드시 따져볼 것
핵심 기능 섹션에서 도구별 단점을 짚었지만, 제품 전반에 걸친 구조적 한계도 별도로 정리할 가치가 있습니다.
한계 1 — ‘검증 가능한 문제’라는 본질적 경계
공동창업자 Anand Kannappan은 현재 회사가 ‘검증 가능한(verifiable)’ 문제에 집중하고 있으며, 검증이 매우 어렵거나 사실상 불가능한 영역이 훨씬 많다고 직접 인정했습니다. (출처: techcrunch.com) 코드가 컴파일되는지, 테스트가 통과하는지처럼 정답이 명확한 작업은 시뮬레이션으로 보상·페널티를 설계하기 쉽습니다. 그러나 “이 고객 응대 톤이 적절한가”, “이 의사결정이 윤리적으로 타당한가"처럼 정답이 모호한 작업에는 이 방식이 잘 들어맞지 않습니다. 에이전트의 실제 위험이 종종 이 ‘검증 불가능한’ 회색지대에서 발생한다는 점을 생각하면, 이것은 도구의 근본적 적용 한계입니다.
한계 2 — 투명한 정찰제 가격의 부재
Patronus는 공개된 정찰제 단가를 제시하지 않습니다. 가격은 인프라 범위, 평가 볼륨, 사용 깊이에 따라 협상형으로 책정되며, 외부에 돌아다니는 단가는 모두 제3자 추정치에 의존합니다. (제3자 집계 기반, 공식 미확정) 초기 도입을 검토하는 소규모 팀 입장에서는 비용을 사전에 가늠하기 어렵고, 도입 의사결정의 불확실성이 커집니다.
한계 3 — 신생 카테고리의 경쟁 구도
에이전트 평가·시뮬레이션은 아직 자리를 잡지 못한 신생 카테고리입니다. Patronus는 AI 랩 내부의 자체 평가팀과 직접 경쟁하는 위치에 있습니다. (출처: techcrunch.com) 대형 AI 랩이 이 기능을 내부화하거나 클라우드 사업자가 유사 기능을 번들로 제공하기 시작하면, 외부 전문 솔루션으로서의 입지가 흔들릴 수 있습니다. (시장 구조에 근거한 추정)
요금 / 한도
Patronus의 가격 정보는 공식적으로 제한적으로만 공개되어 있으므로, 아래 수치 중 제3자 추정치는 별도로 표시합니다.
- Pay-as-you-go (API): 약 $10~20 / 1,000 API calls, 신규 사용자 $5 무료 크레딧. 단, 이는 제3자 집계 수치이며 공식 단가로 확정되지 않았습니다. (출처: theseaitools.com)
- Patronus AI Platform (AWS Marketplace): AWS Marketplace에 등록된 계약형 가격으로, 공개 단가는 게시되어 있지 않습니다. (출처: aws.amazon.com)
- 투자 규모(참고 지표): 2026년 6월 Greenfield Partners 주도로 5,000만 달러 시리즈 B를 유치했으며, 누적 투자액은 7,000만 달러입니다. 투자사에 Lightspeed, Datadog, Samsung 등이 포함됩니다. (출처: patronus.ai)
- Percival 성능 지표: 에이전트 trace에서 20개 이상의 실패 모드 감지, 워크플로 분석 시간 약 1시간 → 1~90초 단축. (출처: patronus.ai/percival)
요약하면, 실제 도입 비용은 영업팀과의 협상을 통해 확정되는 구조이며, 위의 API 단가는 참고용 추정치로만 받아들이는 것이 안전합니다.
비교표
| 항목 | Patronus AI | AI 랩 내부 평가팀 | 일반 LLM 옵저버빌리티 도구 |
|---|---|---|---|
| 핵심 접근 | 디지털 월드 시뮬레이션 + RL 훈련 | 자체 인력·내부 도구 | trace 로깅·모니터링 중심 |
| 사람 개입 | 자동 평가, 사람 개입 없음 | 사람 중심 검수 | 사람이 대시보드 해석 |
| 강점 도메인 | 코딩·금융 등 검증 가능 영역 | 해당 랩의 전용 모델 | 도메인 무관, 사후 관찰 |
| 가격 투명성 | 협상형, 정찰제 없음 | 비공개(내부 비용) | 대체로 공개 단가 존재 |
| 디버깅 도구 | Percival (20+ 실패 모드) | 내부 자체 도구 | 알림·필터 위주 |
표의 ‘일반 LLM 옵저버빌리티 도구’ 열은 카테고리 일반 특성에 대한 추정입니다.
추천 대상
- 복잡한 멀티스텝 에이전트를 운영 배포하려는 팀 — 결제·내부 시스템 조작처럼 실패 비용이 큰 워크플로를 다룬다면 사전 시뮬레이션의 가치가 큽니다.
- 코딩·금융 등 ‘검증 가능한’ 도메인의 개발자 — 정답이 명확한 작업일수록 RL 기반 평가가 잘 맞습니다.
- 에이전트 trace 디버깅에 시간을 많이 쓰는 팀 — Percival의 자동 실패 모드 감지가 수동 분석 부담을 줄여줄 수 있습니다. (출처: patronus.ai/percival)
반대로, 정답이 모호한 정성적 판단이 핵심인 에이전트를 다루거나, 사전에 비용을 정확히 고정해야 하는 소규모 팀이라면 도입을 신중히 검토하는 것이 좋습니다.
FAQ
Q1. Patronus AI는 실제 사용자 데이터로 에이전트를 테스트하나요? 아니요. 핵심은 웹사이트·내부 시스템을 복제한 시뮬레이션 환경(디지털 월드 모델)에서 테스트하는 것입니다. 실제 트래픽에 노출하기 전 가상 환경에서 스트레스 테스트하는 구조입니다. (출처: techcrunch.com)
Q2. 가격이 정확히 얼마인가요? 공식 정찰제는 없습니다. AWS Marketplace 계약형이며, 단가는 인프라 범위·평가 볼륨에 따라 협상으로 정해집니다. 외부에 알려진 “$10~20 / 1,000 API calls” 같은 수치는 제3자 추정치입니다. (출처: theseaitools.com, aws.amazon.com)
Q3. Percival은 어떤 문제를 해결하나요? 에이전트 실행 trace를 분석해 20개 이상의 실패 모드를 자동 감지하고 최적화를 제안합니다. 회사는 워크플로 분석 시간을 약 1시간에서 1~90초로 줄였다고 밝힙니다. 다만 실제 단축 효과는 워크플로 복잡도에 따라 크게 달라질 수 있습니다. (출처: patronus.ai/percival)
참고 링크
- Patronus AI 시리즈 B 발표: patronus.ai/announcements
- TechCrunch 보도: techcrunch.com
- Percival 디버거: patronus.ai/percival
- AWS Marketplace 등록: aws.amazon.com
- 제3자 가격 집계(비공식): theseaitools.com
- Playground 접근: dwm.patronus.ai/playground